
Most AI products are killed by architecture before they are killed by competition.
Picture this: a fintech startup builds a genuinely impressive document review tool. Faster than human review, competitively priced, technically sound. They invest months in landing a proof of concept with a major bank — demos, technical evaluations, stakeholder buy-in across the organization. Then the deal hits procurement. The bank's information security policy categorically prohibits customer financial data from touching any external API endpoint. No exceptions for strong encryption. No carve-outs for anonymization. The policy exists because regulators expect it to exist.
The deal dies. Not because the product failed, but because the product was designed around an assumption that the customer was never going to accept.
That assumption — that inference happens in the cloud — is baked into the default way most AI products get built today. And it creates a ceiling that's invisible until it's expensive.
On-device LLMs flip that assumption. These are large language models that run inference locally, on the hardware itself, without routing requests to a remote server. No API latency, no per-query cloud costs, no data leaving the device. The model travels with the user.
On-device inference transforms AI from a networked service into a durable, portable capability. That's not a technical nicety — it's a commercial unlock.
This shift is now viable at production scale, driven by three converging forces:
The engineering challenge isn't whether on-device LLMs work. They do. The challenge is navigating the tradeoffs between model capability, memory footprint, inference speed, and deployment complexity — and making those tradeoffs deliberately rather than discovering them in production.
This guide walks through those decisions: how to determine where on-device inference fits your product, how to select and size a model, how to architect for hybrid routing, and how to make every routing decision auditable. Whether you're evaluating this for a specific use case or building a deployment roadmap, the goal is to give you decision frameworks you can act on immediately.
Here's the uncomfortable pattern: the industries with the deepest AI budgets are precisely the industries operating under the strictest data residency, sovereignty, and security requirements.
These organizations aren't difficult customers or edge cases. They are the customers — the ones writing the largest checks. And they share a non-negotiable requirement: the data cannot leave the controlled environment.
Cloud inference is the path of least resistance during development. It's fast to prototype, easy to iterate, and unconstrained by hardware limits. So teams build for it, ship for it, and go to market with it. The assumption hardens into architecture. The architecture becomes a sales ceiling that nobody notices until a deal collapses in procurement.
The organizations willing to pay the most for AI capabilities are often the ones whose regulatory and security requirements make cloud-only inference architecturally impossible to sell them.
On-device and on-premise LLM deployment isn't a niche technical preference. It's the prerequisite for entering the market segment with the highest willingness to pay. Understanding how to engineer it — and what it actually costs in complexity — is rapidly becoming a core commercial competency.
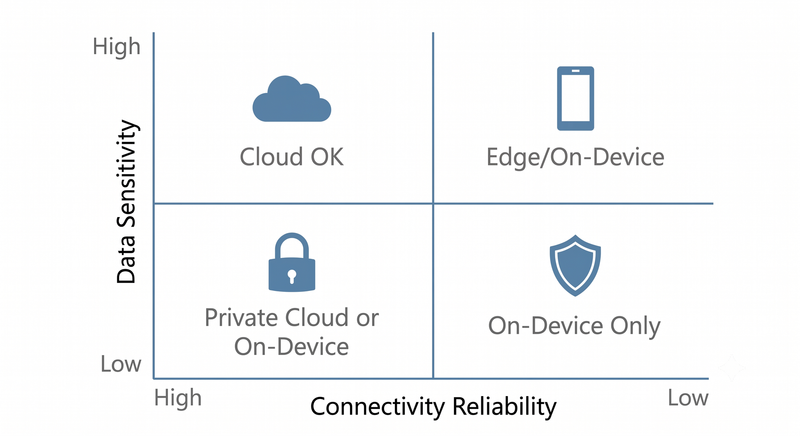
Before evaluating models or benchmarking latency, answer one honest question: where will your product actually be used, and what data will it touch?
Two variables — data sensitivity and connectivity reliability — determine almost everything about your deployment architecture. Not your cloud provider preference. Not your engineering team's comfort with a particular stack. The environment your users actually operate in.
| High Connectivity | Low Connectivity | |
|---|---|---|
| Low Data Sensitivity | ☁️ Cloud works. Ship it. | 📱 On-device or edge — connectivity is the constraint. |
| High Data Sensitivity | 🔒 On-device or private cloud — compliance is the constraint. | 🏗️ On-device, full stop. No alternative exists. |
Zone 1 — Low sensitivity, reliable connectivity. A consumer recipe app with stable internet. Cloud inference is cost-effective and simple. Adding on-device complexity here buys you nothing.
Zone 2 — Low sensitivity, unreliable connectivity. A field service app for utility technicians. Cloud inference covers most workflows — until a technician enters an RF-shielded substation. The AI assistant goes dark for exactly the work where it would deliver the most value.
Zone 3 — High sensitivity, reliable connectivity. A legal document review platform handling privileged communications. The network is fine. Routing client data through a third-party inference API is not.
Zone 4 — High sensitivity, unreliable connectivity. A mobile diagnostic tool for clinicians in rural facilities. Patient data can't leave the device, and the network can't be relied upon. On-device is the only architecture that functions.
The most common architectural mistake isn't choosing the wrong deployment model. It's choosing a deployment model before honestly mapping where the product will be used and by whom.
Most products don't land cleanly in a single quadrant — and that's fine. The exercise still works because it forces you to identify your highest-stakes users, not just your average ones. The substation inspector may not represent the majority of your user base. But they might be the reason the product exists.
Encryption is a technical property. It is not a legal defense. Regulators and courts don't ask how data traveled — they ask whether it did.
This distinction tends to surface late in the sales cycle. After your team has scoped the integration. After engineering has built the pipeline. After the demo landed well with the customer's product team. Then legal reviews the architecture, and the deal stalls. The sunk cost is real.
The compliance event is data leaving the device. Everything downstream — TLS, signed DPAs, SOC 2 certifications — becomes secondary once that threshold is crossed.
Take litigation support software as an example. A tool that sends case strategy queries through a third-party LLM endpoint — even one with ironclad contractual protections — creates a viable argument for attorney-client privilege waiver. The legal question isn't whether the vendor is trustworthy. It's whether confidential communications were disclosed to a third party. They were. The data moved. That movement is the event.
The same logic applies across regulated verticals:
If the answer to question three is "we call an external API," you don't have a compliance strategy. You have a compliance problem that hasn't been discovered yet.
In these contexts, on-device inference isn't a performance optimization. It's the only architecture that eliminates the transmission event entirely. The model runs locally. The data stays local. There is nothing for a regulator to characterize or a court to scrutinize.
This is where teams most commonly go sideways. They treat model selection as a research problem — benchmarking perplexity scores, comparing MMLU results, chasing the highest-performing open-weight model available. Then they ship something that doesn't fit on the target device, doesn't understand the domain, and impresses nobody who matters.
Model selection is a product specification exercise. The engineering follows from product clarity, not the reverse.
Consider a customer support tool for a mid-size retail brand. A general-purpose 7B model sounds compelling in demos — articulate, broad, handles edge cases gracefully. But it consistently fumbles specific return policy logic, misidentifies SKUs, and struggles with the shorthand real support agents use daily. A fine-tuned 2B model, trained on six months of resolved support tickets, outperforms it on every metric that actually matters to the business. And it runs on mid-tier Android devices with memory to spare.
Bigger isn't better. Relevant is better.
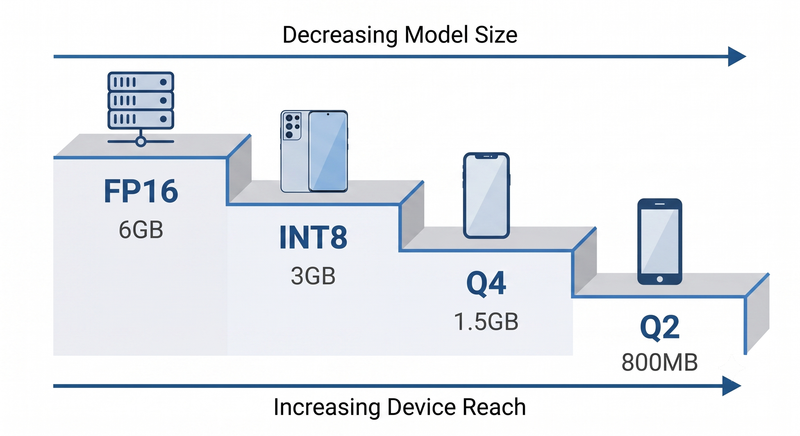
Think of quantization not as a quality degradation path, but as a device reach curve. Every step down opens the product to a wider hardware install base.
| Format | ~Size (3B model) | Deployment Verdict |
|---|---|---|
| FP16 | ~6 GB | Impractical for most mobile hardware |
| INT8 | ~3 GB | Tight — flagship devices only |
| Q4 | ~1.5 GB | Viable — broad mid-range device coverage |
| Q2 | ~800 MB | Aggressive — wide reach, quality is task-dependent |
The engineering question reframes entirely: what's the minimum quality threshold for this specific task, and what's the maximum device reach achievable at that threshold?
For the retail support tool, Q4 may preserve enough domain accuracy to be indistinguishable from FP16 on the tasks that matter. For a medical documentation assistant, INT8 might be the floor below which you can't go.
The VRAM ceiling is a product constraint, not a hardware footnote. If your target device has 4 GB of shared memory and your model needs 6 GB, you don't have a deployment — you have a prototype. Define your device floor before you finalize your model choice.
Product requirements set the quality floor. The quantization ladder determines your reach. Work in that order.
Here's a failure mode that unfolds slowly enough that nobody notices until it's expensive.
A product team ships a cloud-based AI feature. Six months later, they need an offline version. Instead of revisiting the original architecture, they build a parallel system — separate codebase, separate prompt engineering, separate QA pipeline. It feels pragmatic in the moment.
By month twelve, a bug fix applied to the cloud path never reaches the offline path. The product behaves differently depending on connectivity in ways nobody planned, nobody documented, and nobody can fully explain. The eventual consolidation rewrite could have been avoided with a single interface decision at the start.
The pattern is straightforward. Three components:
ModelRepository interface — defines what the AI capability does, with no opinion on where it runsModelRepositoryFactory — the single location where routing logic lives// The contract (pseudocode)
interface ModelRepository {
generateResponse(prompt: string): Response
summarize(content: string): Summary
}
// Cloud implementation
class CloudModelRepository implements ModelRepository { ... }
// On-device implementation
class OnDeviceModelRepository implements ModelRepository { ... }
// The only place routing decisions are made
class ModelRepositoryFactory {
static create(context: DeviceContext): ModelRepository {
if (context.isOnline && context.taskRequiresCloud) {
return new CloudModelRepository()
}
return new OnDeviceModelRepository()
}
}
The rest of the application never asks where inference happens. It calls ModelRepository and gets a response. That's it.
The ModelRepositoryFactory is the single location where routing logic lives — and that's the entire point. When you need to audit why a particular user received a cloud response instead of a local one, you look in exactly one place.This matters for debugging, for compliance reviews, and for the next engineer who inherits the codebase. Routing logic scattered across feature files is a maintenance liability. Routing logic centralized in a factory is a policy you can read, test, and modify in an afternoon.
The architecture doesn't just support on-device inference — it makes adding it additive rather than disruptive.
In regulated industries, routing logic — the decision about when to run inference locally versus in the cloud — isn't just a technical concern. It's a compliance artifact.
"The system decided locally" won't satisfy a compliance officer. "The system routed locally because the data sensitivity flag was set and the device was offline, per policy version 2.3, at 14:32 UTC" will.
Consider a healthcare organization deploying an AI documentation assistant. Their compliance team doesn't just want PHI processed on-device. They want a timestamped log proving that every query containing PHI was routed locally, along with the specific policy rule that triggered the decision. The routing layer isn't infrastructure plumbing — it's evidence.
Routing decisions should be explicit, logged, and configurable without a release cycle. Opacity in routing is a liability in any regulated context.
Treat these as a ranked hierarchy. Higher-priority rules override lower ones unconditionally:
| Criterion | Cloud | Local |
|---|---|---|
| Latency | Variable, network-dependent | Consistent, typically sub-100ms |
| Cost at scale | Per-token, compounds quickly | Fixed hardware amortization |
An on-device LLM is a large language model that runs inference locally on the device itself, without routing requests to a remote server or external API. No data leaves the hardware, no cloud costs accumulate per query, and the model functions whether or not the device has network connectivity. The model travels with the user — which transforms AI from a networked service into a durable, portable capability.
On-device LLMs matter for enterprise sales because the highest-paying customers — hospitals, law firms, defense contractors, financial institutions — operate under data residency and security requirements that make cloud-only inference architecturally impossible to sell them. A product built exclusively around cloud inference has an invisible ceiling that only becomes visible when a deal collapses in procurement. The organizations writing the largest AI checks are frequently the ones whose policies categorically prohibit customer data from touching an external API endpoint.
Quantization reduces a model's memory footprint by representing weights at lower numerical precision — shrinking a capable model from tens of gigabytes down to a range that fits on consumer hardware. A 3B-parameter model drops from roughly 6 GB at FP16 to approximately 1.5 GB at Q4, which is the difference between "flagship devices only" and "broad mid-range coverage." The engineering question isn't how much quality you're willing to sacrifice — it's what the minimum quality threshold is for your specific task, and what device reach is achievable at that threshold.
Define a single ModelRepository interface that specifies what the AI capability does, then build two concrete implementations — one for cloud, one for on-device — behind a factory that owns all routing logic. The rest of the application calls the interface and receives a response; it never asks where inference happened. Centralizing routing in one factory means you can audit, test, and modify the decision logic in an afternoon rather than hunting through scattered feature files.
Use cloud inference when data sensitivity is low, connectivity is reliable, and the task genuinely exceeds what a compressed local model can handle — long-context summarization, complex multi-step reasoning, or workloads where model quality differences are measurable and matter to the business outcome. Cloud inference is also the right default during early prototyping, when iteration speed matters more than deployment constraints. The mistake isn't choosing cloud — it's choosing cloud before honestly mapping where the product will be used and what data it will touch.
Encryption is a technical property, not a legal defense — regulators and courts ask whether data left the device, not how it was protected in transit. A litigation support tool that routes case strategy queries through a third-party LLM endpoint creates a viable attorney-client privilege waiver argument regardless of the vendor's SOC 2 certification or contractual protections. The compliance event is the transmission itself. On-device inference eliminates that event entirely; everything else is downstream of it.
On-device inference runs the model on the end-user's hardware — a phone, laptop, or embedded system — with no network dependency required. Edge deployment typically refers to inference running on nearby infrastructure (a local server, gateway device, or regional node) that reduces latency compared to cloud but still involves a network hop and a separate compute environment. For use cases where data cannot leave a controlled environment at all, on-device is the only architecture that fully eliminates the transmission event.
Build routing logic that logs the specific policy rule, data sensitivity flag, connectivity state, and timestamp behind every decision — not just the outcome. "The system routed locally" won't satisfy a compliance officer; "the system routed locally because the PHI sensitivity flag was set and the device was offline, per policy version 2.3, at 14:32 UTC" will. Treat the routing layer as a compliance artifact, not infrastructure plumbing, and make it configurable without requiring a release cycle.